
SillyTavern AI How To Install And Use It? The Nature Hero

Silly Tavern Install Guide Many Free AI Characters await! YouTube

Silly Tavern AI How To Install And Use It? power ai prompts
![Silly Tavern Overview & How to Get Started [Aug 2023]](https://i2.wp.com/approachableai.com/wp-content/uploads/2023/06/silly-tavern-featured.jpg)
Silly Tavern Overview & How to Get Started [Aug 2023]

How To Use Silly Tavern Characters? The Nature Hero
![Silly Tavern Overview & How to Get Started [Aug 2023]](https://i2.wp.com/approachableai.com/wp-content/uploads/2023/06/silly-tavern-user-settings.png)
Silly Tavern Overview & How to Get Started [Aug 2023]
![Silly Tavern Overview & How to Get Started [Aug 2023]](https://thenaturehero.com/wp-content/uploads/2023/05/importing-from-characterhub-to-sillytavern.png)
You can set a maximum number of tokens for each response to.
Silly tavern response length. (all other sampling methods are disabled) Web wiki security insights new issue [bug] sillytavern takes >15 seconds to send a request to proxy server with long conversations (>6000 context tokens) #228. Presence penalty should be higher.
Web if you want even more exacting control over the humor used in the q & a session, you can use a very common q & a technique. Be sure to choose carefully if you want to become the champion! If supported by the api, you can.
I keep trying to get a response but the ai cant. Most models have context sizes up to. Web the internal equivalent to response length (tokens) should be set to first chunk (tokens) or next chunks (tokens) while the new option is true.
Web sillytavern doesn't generate the responses. So im wondering what settings are good for fast and good responses? Web 1.5 temp for crazy responses.
Web silly question definition: Web here are my settings for tavern, not necessarily the best. Web whats the best setting for silly tavern?
Ago 'memory' when it comes to ai chat bots is a tricky thing. You shouldn't have to go lower than 3.5k though. The larger the parameter value, the longer the generation time takes.

Silly Tavern AI A Guide To An Interactive Chat Experience Dataconomy

Silly Tavern AI A Guide To An Interactive Chat Experience Dataconomy

GitHub Hyreos/TavernAI Silly TavernAI mod
What is SillyTavern? docs.ST.app

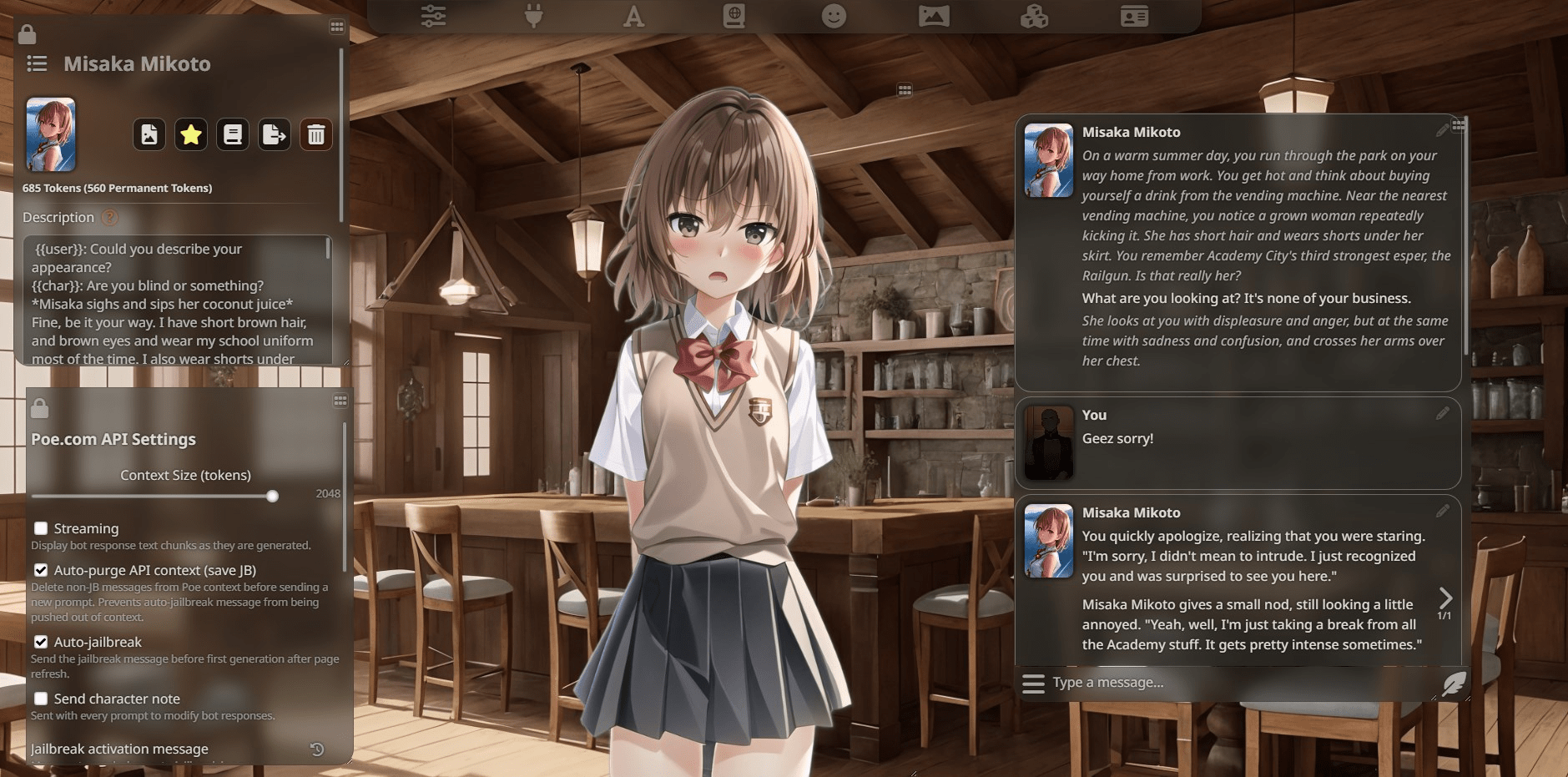
How To Use Silly Tavern Characters? The Nature Hero

How To Use Silly Tavern Characters? The Nature Hero

How To Use Silly Tavern Characters? The Nature Hero
![Silly Tavern New AI Chat Experience & Setup [June 2023]](https://i2.wp.com/thegptime.com/wp-content/uploads/2023/06/Silly-Travern.jpg)
Silly Tavern New AI Chat Experience & Setup [June 2023]

How To Use Silly Tavern Characters? The Nature Hero

21 Clever Yet Funny Bar Signs That Will Entice You To Step In and Grab

Toolbar not appearing for Silly Tavern? The top ain't appearing. I

25 Hilarious Bar Signs Gallery eBaum's World

Silly Tavern AI A Guide To An Interactive Chat Experience Dataconomy

